
1 Transformer
1.1 Representation Learning for NLP
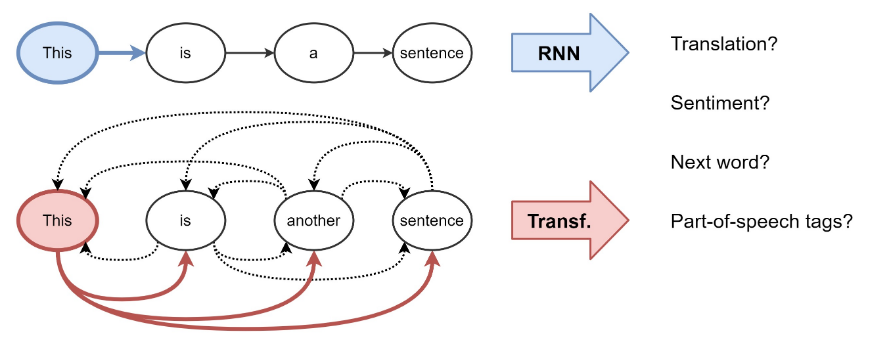
- NNs build representations of input data as vectors/embeddings, which encode useful statistical and semantic information about the data.
- For NLP:
- Recurrent Neural Networks (RNNs): sequential manner, i.e., one word at a time.
- Transformers: attention mechanism to figure out how important all
the other words in the sentence are w.r.t. to the aforementioned word.
- The weighted sum of linear transformations of the features of all the words
1.2 Breaking down the Transformer
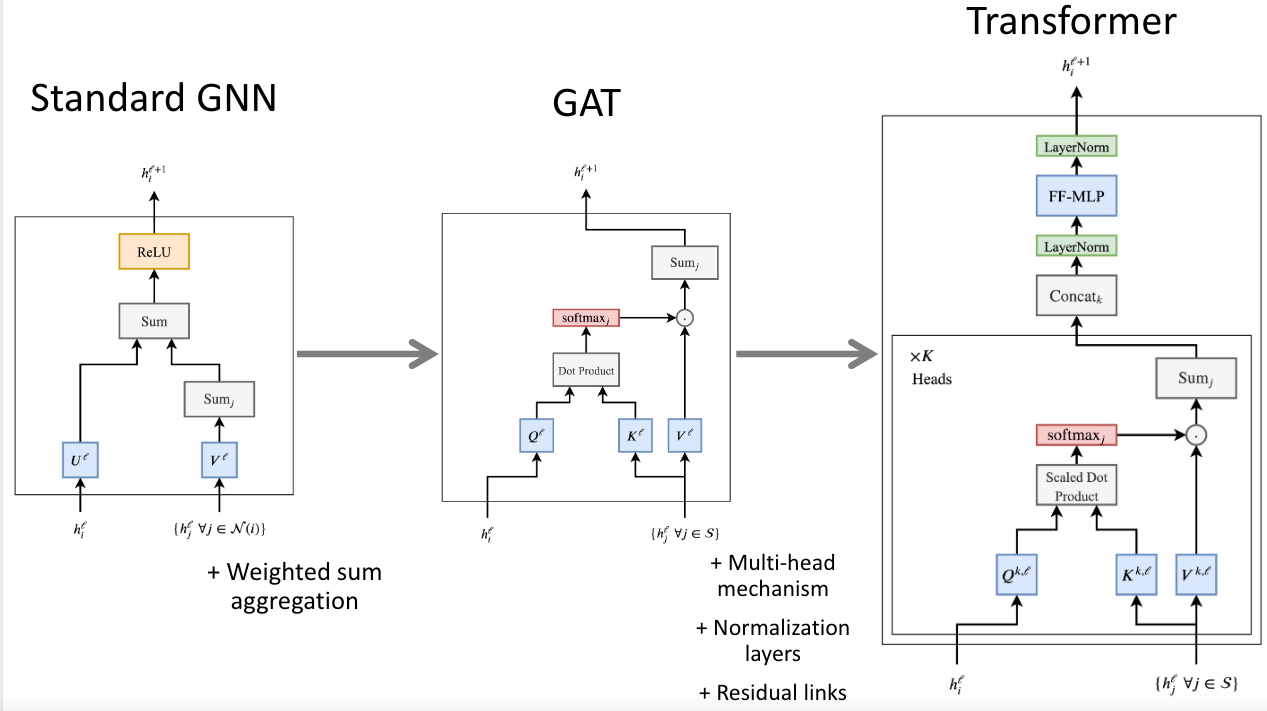
The Transformer architecture. 1.
2.
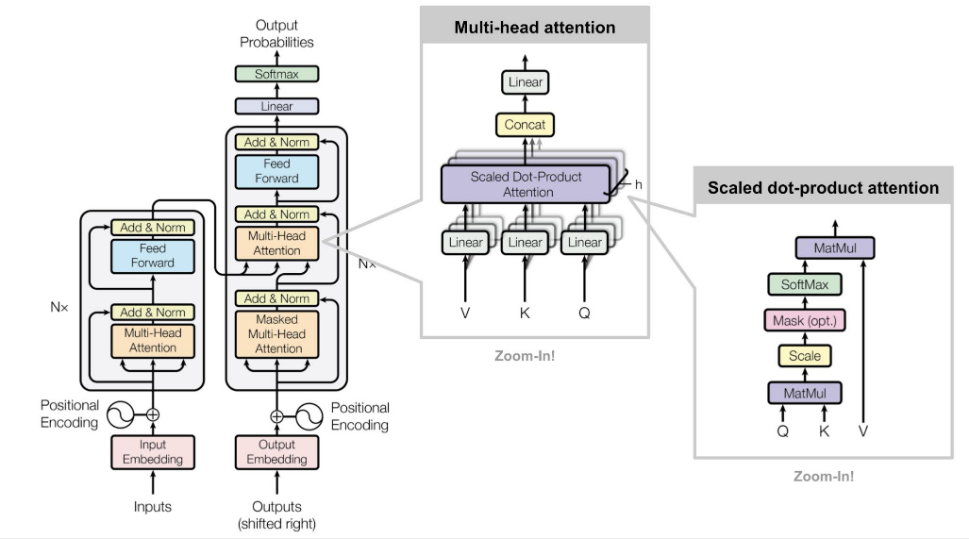
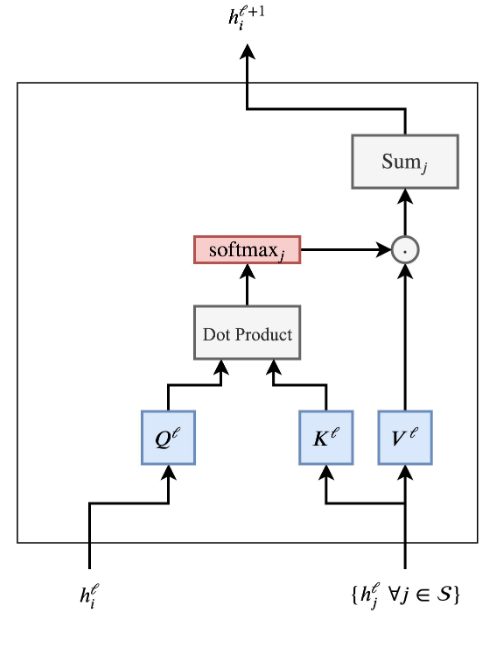
- The hidden feature
of the -th word in a sentence from layer to layer is updated as: are learnable linear weights (denoting the Query, Key and Value for the attention computation, respectively). - Attention mechanism pipeline:
- Multi-head attention mechanism:
is a down-projection to match the dimensions of and across layers. - Motivation: bad random initializations for dot-product attention mechanism can de-stabilize the learning process.
1.3 Scale Issues and the Feed-forward Sub-layer
- Motivation: the features for words after the attention mechanism
might be at different scales or magnitudes.
- Issue 1: Some words having very sharp or very
distributed attention weights.
- Scaling the dot-product attention by the square-root of the feature dimension
- Issue 2: Each of multiple attention head outputs
values at different scales.
- LayerNorm: normalizes and learns an abne transformation at the feature level.
- Issue 1: Some words having very sharp or very
distributed attention weights.
- Another 'trick' to control the scale issue: a position-wise 2-layer
MLP:
- Stacking layers: Residual connections between the inputs and outputs of each multi-head attention sub-layer and the feed-forward sub-layer.
2 GNNs
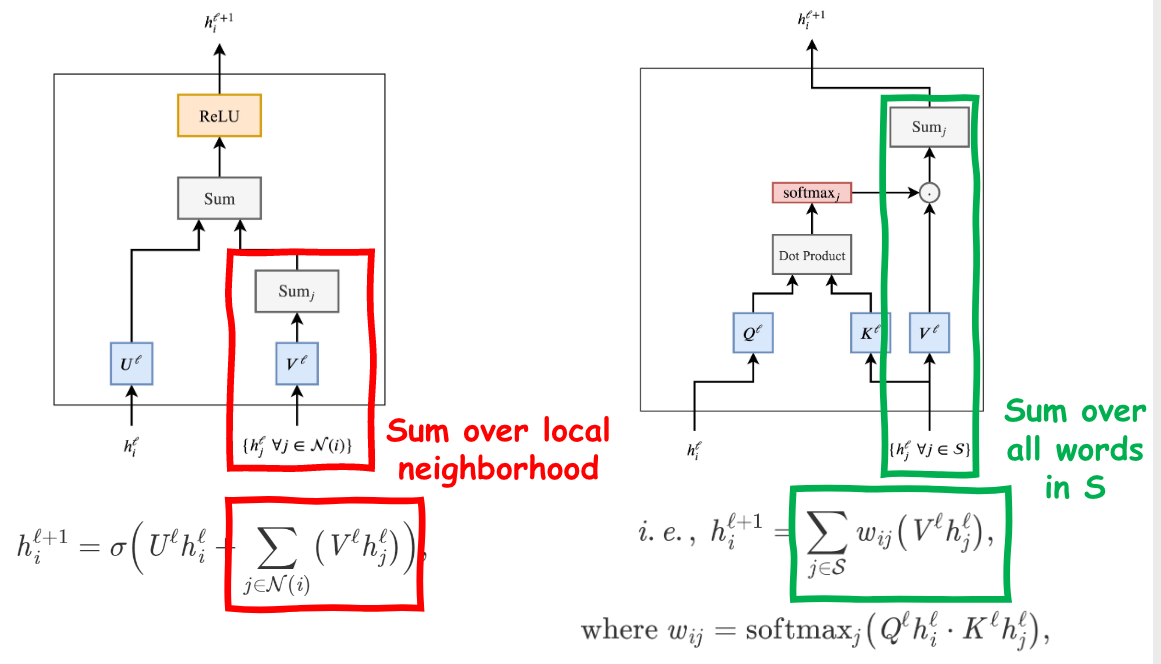
- Neighborhood aggregation (or [[message passing]])
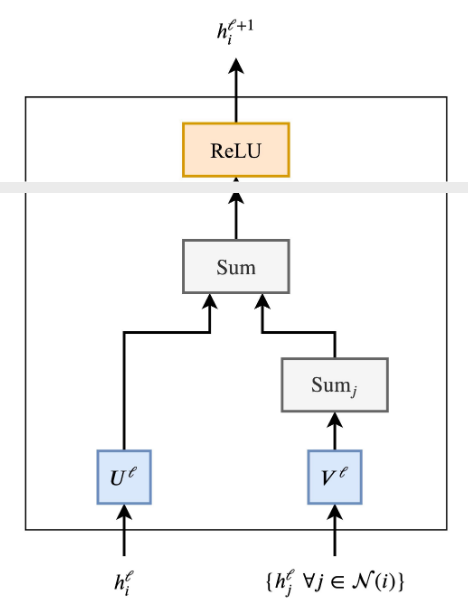
- Each node gathers features from its neighbors to update its
representation of the local graph structure around it.
are learnable weight matrices of the GNN layer. is a non-linearity such as ReLU. - The summation over the neighborhood nodes can be replaced by other
input size-invariant aggregation functions.
- Mean
- Max
- Weighted sum via an attention mechanism
- Each node gathers features from its neighbors to update its
representation of the local graph structure around it.
- Stacking several GNN layers enables the model to propagate each node's features over the entire graph.
3 Transformers Are GNNs
3.1 Sentences Are Fully-connected Word Graphs
Consider a sentence as a fully-connected graph, where each word is connected to every other word.
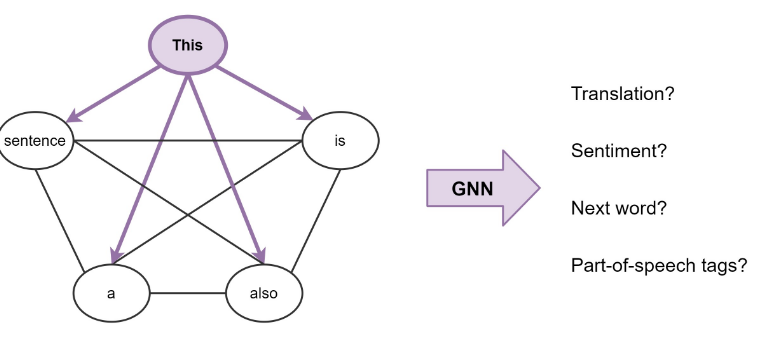
Transformers are GNNs with multi-head attention as the neighborhood aggregation function.
- Transformers: entire fully-connected graph.
- GNNs: local neighborhood.
3.2 What Can We Learn from Each Other?
3.2.1 Are Fully-connected Graphs the Best Input Format for NLP?
- Linguistic structure
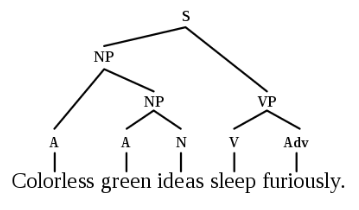
- Syntax trees/graphs.
- Tree LSTMs.
3.2.2 How to Learn Long-term Dependencies?
- Fully-connected graphs make learning very long-term dependencies
between words difficult.
- In an
word sentence, a Transformer/GNN would be doing computations over pairs of words.
- In an
- Making the attention mechanism sparse or adaptive in terms of input
size.
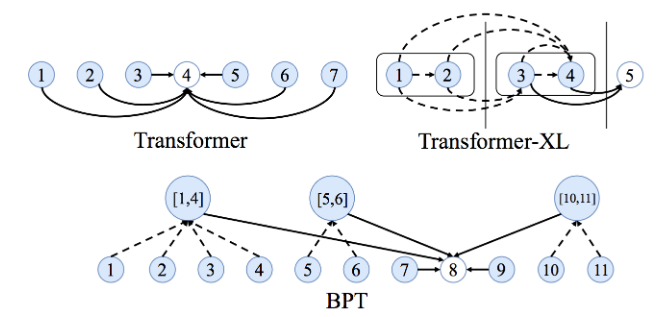
- Adding recurrence or compression into each layer.
- Locality Sensitive Hashing.
3.2.3 Are Transformers Learning 'neural Syntax'?
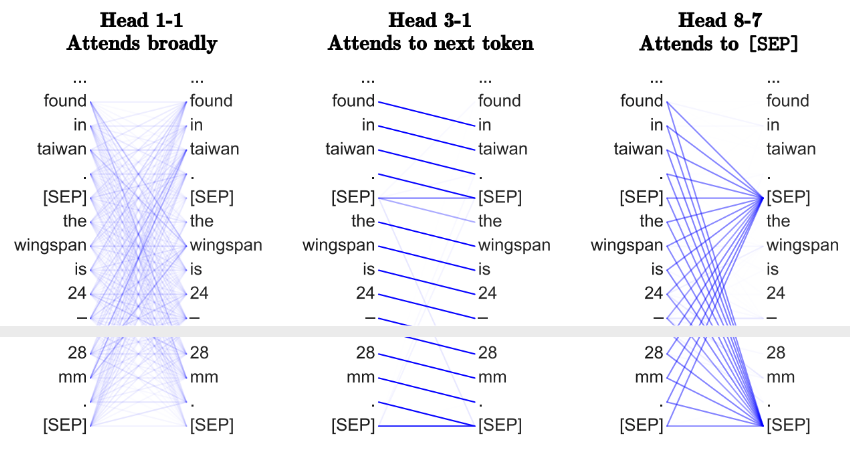
- Attention for identifying which pairs are the most interesting enables Transformers to learn something like a task-specific syntax.
- Different heads can be considered as different syntactic properties.
3.2.4 Why Multiple Heads of Attention? Why Attention?
- The optimization view: having multiple attention heads improves learning and overcomes bad random initializations.
- GNNs with simpler aggregation functions such as sum or max do not require multiple aggregation heads for stable training.
- ConvNet architecture
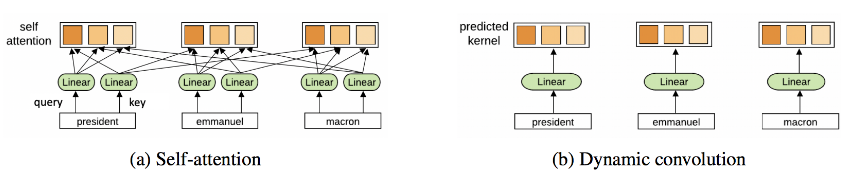
3.2.5 Why is Training Transformers so Hard?
- Hyper-parameter: Learning rate schedule, warmup strategy and decay settings.
- The specific permutation of normalization and residual connections within the architecture.