
1 📑Metadata
[!abstract] 摘要
Graph neural networks are powerful architectures for structured datasets. However, current methods struggle to represent long-range dependencies. Scaling the depth or width of GNNs is insufficient to broaden receptive fields as larger GNNs encounter optimization instabilities such as vanishing gradients and representation oversmoothing, while pooling-based approaches have yet to become as universally useful as in computer vision. In this work, we propose the use of Transformer-based self-attention to learn long-range pairwise relationships, with a novel "readout" mechanism to obtain a global graph embedding. Inspired by recent computer vision results that find position-invariant attention performant in learning long-range relationships, our method, which we call GraphTrans, applies a permutation-invariant Transformer module after a standard GNN module. This simple architecture leads to state-of-the-art results on several graph classification tasks, outperforming methods that explicitly encode graph structure. Our results suggest that purely-learning-based approaches without graph structure may be suitable for learning high-level, long-range relationships on graphs.
[!summary] 结论
We proposed GraphTrans, a simple yet powerful framework for learning long-range relationships with GNNs. Leveraging recent results that suggest structural priors may be unnecessary or even counterproductive for high-level, long-range relationships, we augment standard GNN layer stacks with a subsequent permutation-invariant Transformer module. The Transformer module acts as a novel GNN "readout" module, simultaneously allowing the learning of pairwise interactions between graph nodes and summarizing them into a special token's embedding as is done in common NLP applications of Transformers. This simple framework leads to surprising improvements upon the state of the art in several graph classification tasks across program analysis, molecules and protein association networks. In some cases, GraphTrans outperforms methods that attempt to encode domain-specific structural information. Overall, GraphTrans presents a simple yet general approach to improve long-range graph classification; next directions include applications to node and edge classification tasks as well as further scalability improvements of the Transformer to large graphs.
2 💡Note
2.1 论文试图解决什么问题?
Current GNNs struggle to represent long-range dependencies.
2.2 这是否是一个新的问题?
The issue of transformers on graphs has been explored before.
2.3 这篇文章要验证一个什么科学假设?
Adding a Transformer subnetwork on top of a standard GNN layer stack can obtain SOTA results.
2.4 有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
2.4.1 Graph Classification
- Pooling operation:
- Global: reducing a set of node encodings to a single graph encoding.
- Non-learned mean or max-pooling over nodes
- the "virtual node" approach
- Local: collapsing subsets of nodes to create a coarser graph.
- Learned pooling schemes
- Non-learned pooling methods based on classic graph coarsening schemes
- Global: reducing a set of node encodings to a single graph encoding.
- Notable work
- DAGNN (Directed Acyclic Graph Neural Network)
2.4.2 Transformers on Graphs
- Introducing GNN layers to let nodes attend to other nodes in some surrounding neighborhood via Transformer-style attention.
- Learning long-range dependencies without over smoothing: allowing
nodes to attend to more than just the one-hop neighborhood.
- Take the attended neighborhood radius as a tuning parameter.
- Sample neighborhoods of random size during training and inference.
- Global average pooling over the nodes.
- Positional encodings.
2.4.3 Efficient Transformers
- Less FLOPs.
- Less computation and memory complexity.
- Neural architecture search (NAS)
2.5 🔴论文中提到的解决方案之关键是什么?
2.5.1 Motivation: Modeling Long-Range Pairwise Interactions
- Attempting for long-range learning on graphs have not yet led to
performance increase.
- Stacking GNN layers
- Hierarchical pooling
- Expanding the receptive field of a single GNN layer beyond a one-hop neighborhood is not scalable.
- For CNN:
- Attention layers can learn to reproduce the strong relational inductive biases induced by local convolutions.
- While strong relational inductive biases are helpful for learning local, short-range correlations, for long-range correlations less structured modules may be preferred.
- GraphTrans:
- Long-range relationships are important.
- Using GNN as a backbone + Transformer to learn long-range dependencies with no graph spatial priors.
2.5.2 Learning Global Information with GraphTrans
GraphTrans: A GNN subnetwork followed by a Transformer subnetwork
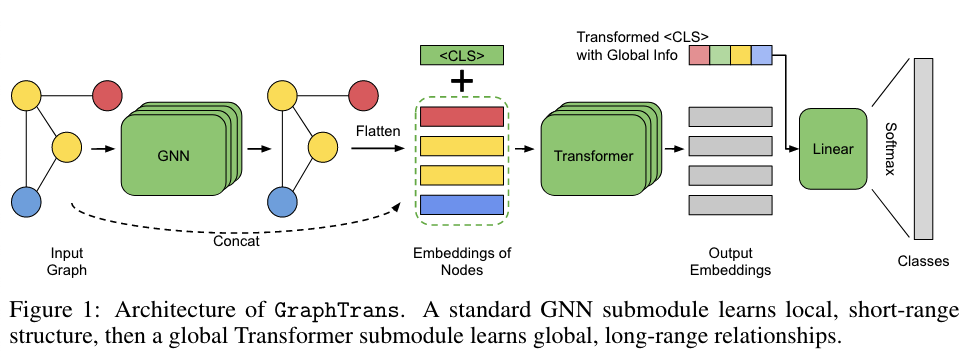
2.5.2.1 GNN Module
A generic GNN layer stack can be expressed as:
2.5.2.2 Transformer Module
Pass the final per-node GNN encodings
- Layer normalization:
- Standard Transformer layer stack:
- Concatenated
encodings are then passed to a Transformer fully-connected subnetwork, consisting of the standard sequence with residual connections.
2.5.2.3
- The whole-graph classification task requires a single embedding vector that describes the whole graph.
- Previous readout methods:
- Simple mean or max pooling;
- Virtual node.
- Cannot learning pairwise relationships between graph nodes.
- Special-token readout
- Append an additional learnable embedding
to the sequence, when feeding . - Take the first embedding
from the transformer output as the representation of the whole graph. - Prediction:
- Append an additional learnable embedding
- This special-token readout mechanism may be viewed as a generalization or a "deep" version of a virtual node readout. ## 2.6 论文中的实验是如何设计的?
Evaluate GraphTrans on graph classification tasks from three modalities: biology, computer programming, and chemistry.
2.7 用于定量评估的数据集是什么?评估标准是什么?Baseline 是什么?
- 数据集:
- Biological benchmarks
- NCI1
- NCI109
- Chemical benchmarks
- molpcba from the Open Graph Benchmark (OGB)
- Computer programming benchmark
- code2 from OGB
- Biological benchmarks
2.8 论文中的实验及结果有没有很好地支持需要验证的科学假设?
2.8.1 Benchmarking
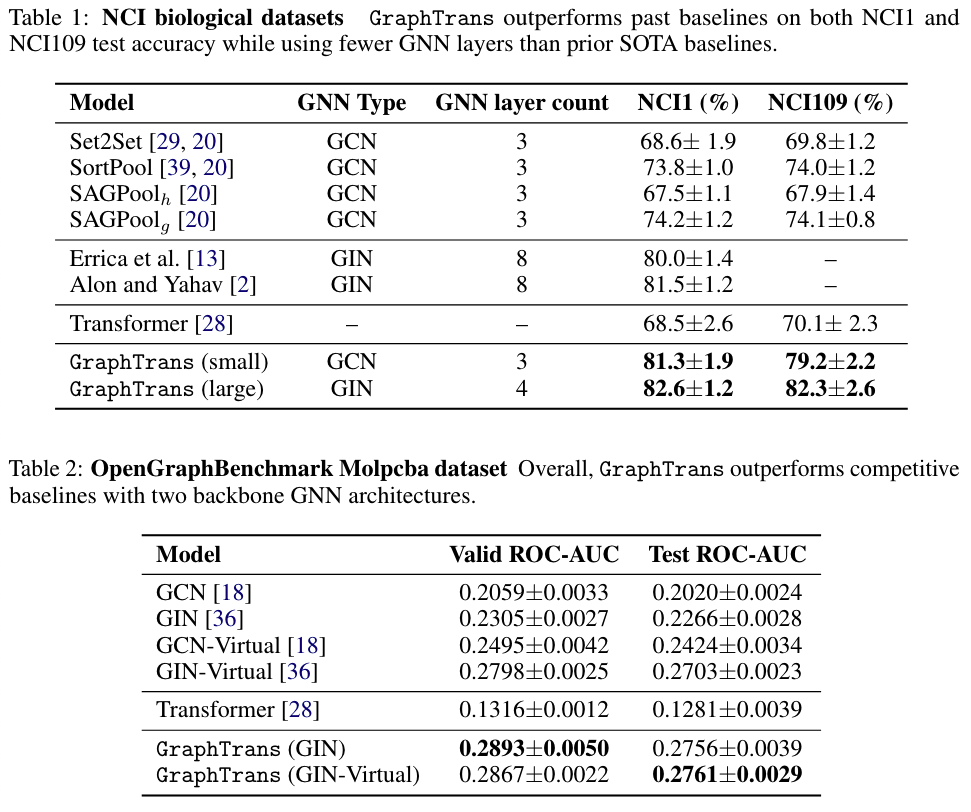
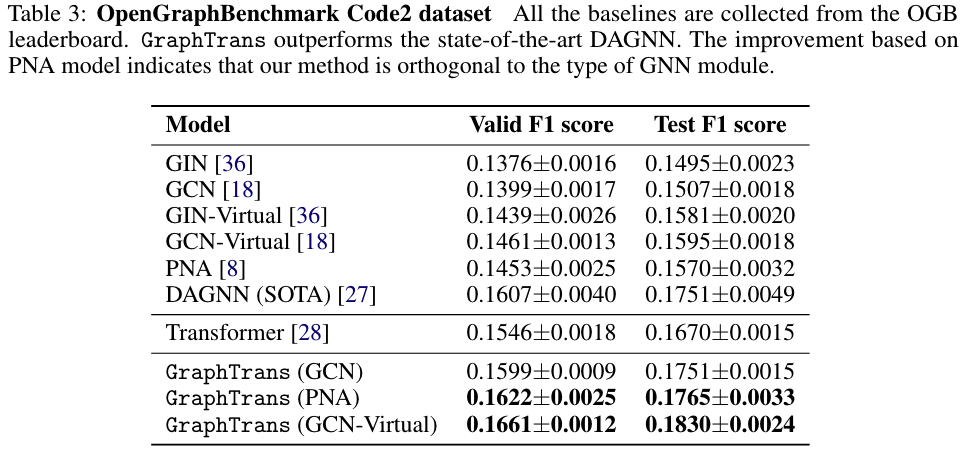
实验结果:
结论:GraphTrans could take benefit from both the local graph structure learned by the GNN and the long-range concept retrieved by the Transformer module based on the GNN embeddings.
2.8.2 Ablation Studies
2.8.2.1 Transformers Can Capture Long-range Relationships
实验结果:
结论:The attention inside the transformer module can capture long-range information that is hard to be learned by the GNN module.

2.8.2.2 Effectiveness of
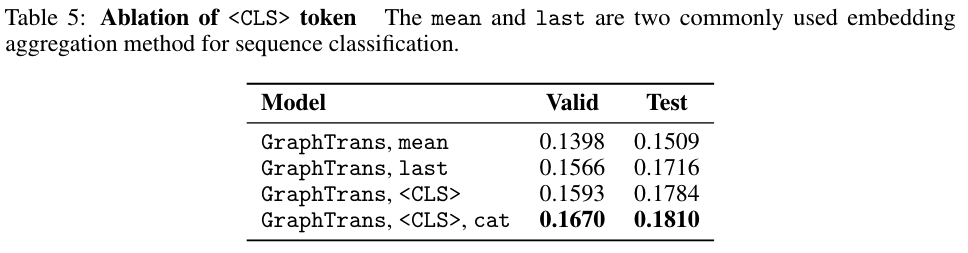
实验结果:
结论:The $$ learns to attend to important nodes in the graph to learn the representation for the whole graph
2.8.3 Parameter Analysis
2.8.3.1 Scalability
实验结果:
结论:GraphTrans model scales at least as well as the GCN model when the number of nodes and edge density increases.
2.8.3.2 Computational Efficiency
实验结果:
结论:For Molpcba and Code2, GraphTrans is faster to train than a comparable GCN model.
2.8.3.3 Number of Parameters
实验结果:
结论:GraphTrans only increases total parameters marginally for Molpcba and NCI.
2.9 这篇论文到底有什么贡献?
- Showing that long-range reasoning via Transformers improve graph neural network (GNN) accuracy.
- Introducing a novel readout module
to replace global pooling and virtual node approaches.
2.10 下一步呢?有什么工作可以继续深入?
- High computational complexity of attention mechanism.
- Positional encoding.
- NAS for GNN module.