
1 📑Metadata
摘要
[[In-context learning]] is the ability of a pretrained model to adapt to novel and diverse downstream tasks by conditioning on prompt examples, without optimizing any parameters. While large language models have demonstrated this ability, how in-context learning could be performed over graphs is unexplored. In this paper, we develop Pretraining Over Diverse In-Context Graph Systems (PRODIGY), the first pretraining framework that enables in-context learning over graphs. The key idea of our framework is to formulate in-context learning over graphs with a novel prompt graph representation, which connects prompt examples and queries. We then propose a graph neural network architecture over the prompt graph and a corresponding family of in-context pretraining objectives. With PRODIGY, the pretrained model can directly perform novel downstream classification tasks on unseen graphs via in-context learning. We provide empirical evidence of the effectiveness of our framework by showcasing its strong in-context learning performance on tasks involving citation networks and knowledge graphs. Our approach outperforms the in-context learning accuracy of contrastive pretraining baselines with hard-coded adaptation by 18% on average across all setups. Moreover, it also outperforms standard finetuning with limited data by 33% on average with in-context learning.
结论
We introduce PRODIGY, the first framework that enables in-context learning on graphs. A model that is pretrained using PRODIGY can seamlessly execute a new classification task over new graphs represented by prompt graph. It markedly surpasses the performance of other baseline models with in-context learning, even those that employ finetuning, in both the node and edge classification tasks.
2 💡Note
2.1 论文试图解决什么问题?
- [[In-context learning]] over graphs.
- How to formulate and represent node-, edgeand graph-level tasks over graphs with a unified task representation that allows the model to solve diverse tasks without the need for retraining or parameter tuning? --> what is an analog of natural language prompting for graph machine learning tasks?
- How to design model architecture and pre-training objectives that enable models to achieve in-context learning capability across diverse tasks and diverse graphs in the unified task representation? --> How to tackle the more difficult setting of generalizing across the graphs and tasks without fine-tuning?
2.2 这是否是一个新的问题?
Yes, this problem is unexplored.
2.3 这篇文章要验证一个什么科学假设?
With the proposed pre-training framework, named PRODIGY, the pre-trained model can directly perform novel downstream classification tasks on unseen graphs via [[In-context learning]].
2.4 有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
2.4.1 In-context Learning of Large Language Models
Pre-trained large language models can make predictions for diverse downstream tasks directly by prompting with a few examples of the task or more generally any textual instructions.
2.4.2 Pre-training on Graphs
- Existing works on pre-training graphs all follow the general paradigm of learning a good graph encoder that can perform pre-training tasks.
- To adapt to any downstream tasks, it then requires fine-tuning a classification head on top of the encoder with large amount of task specific data for each downstream task.
2.4.3 Meta Learning on Graphs
- Existing meta-learning methods are only designed and tested for generalizing across different tasks on the same graph: the methods are trained on a set of training tasks on a graph, then tested over a disjoint but similar set of test tasks over the same graph.
- Exhibit optimal performance only when trained on similar curated tasks.
2.5 🔴论文中提到的解决方案之关键是什么?
[! Summary] Contribution
1. Prompt Graph: an in-context graph task representation 2. PRODIGY: a framework for pre-training an in-context learner over prompt graphs.
2.5.1 In-context Learning over Graphs
2.5.1.1 Classification Tasks over Graphs
A unified formulation, the space of the input
2.5.1.2 Few-shot Prompting
[[少样本学习]]
- For a
-shot prompt with a downstream -way classification tasks with classes: - a small number of input-label pairs
as prompt examples of the task specification --> input-label pairs with label . - a set of queries
that we want to predict labels for.
- a small number of input-label pairs
- Since all input datapoints are nodes/edges/subgraphs from the larger
source graph
, this graph contains critical information and provides contexts for the inputs. - We also need to include the source graph
in the prompt.
- We also need to include the source graph
- The pre-trained model should be able to directly output the
predicted labels for each datapoint in
via in-context learning.
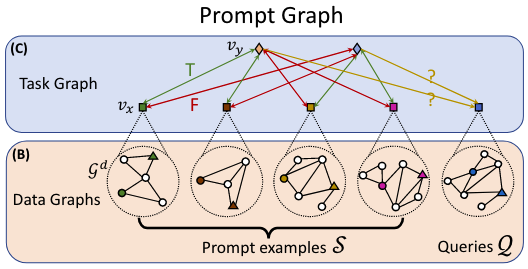
2.5.1.3 Prompt Graph Representation
A prompt graph is composed of data graphs and a task graph.
[!Question] 建模为二部图?
- Data graph
- To gather more information about the
from the source graph without having to represent the entire source graph explicitly. - Perform contextualization of each datapoint
in and in the source graph to form data graphs. - Explicitly retrieving subgraphs
- Implicitly using embedding-based methods
- Sample
-hop neighborhood of in : Neighbor
- To gather more information about the
- Task graph
- To better capture the connection and relationship among the inputs and the labels.
- Node:
- For each data graph
, a data node represents each input. - For each label, there is a label node
. - A task graph contains
data nodes ( prompt examples and queries) and label nodes.
- For each data graph
- Edge:
- For the query set, each query data node will be connected to all the label nodes.
- For the prompt examples, we connect each data node to all the label
nodes, where the edge with the true labels is marked as
while the others are marked as .
2.5.2 Pre-training to Enable In-context Learning
Assume access to a pre-training graph
that is independent of the source graph for the downstream task.
2.5.2.1 Message Passing Architecture over Prompt Graph
- Data graph Message Passing
- Learn node representation
: - Read out a single embedding
: - For node classification -->
: - For link prediction:
- For node classification -->
- Learn node representation
- Task graph Message Passing
- The initial embedding of data node
is . - The embedding of label node
can either be initialized with random Gaussian or additional information available about the labels. - Each edge also has two binary features
that indicate - whether the edge comes from an example or a query
- the edge type of
or .
- Attention-based GNN

- The initial embedding of data node
- Prediction Read Out
- Readout the classification logits
by taking cosine similarity between each pair of query graph representation and label representation
- Readout the classification logits
2.5.2.2 In-context Pre-training Objectives
To pretrain the graph model using a large pretraining graph
independent of the downstream task graph
Pre-training Task Generation
- Neighbor matching
- Multi-task
- Neighbor matching
Prompt Graph Generation with augmentation
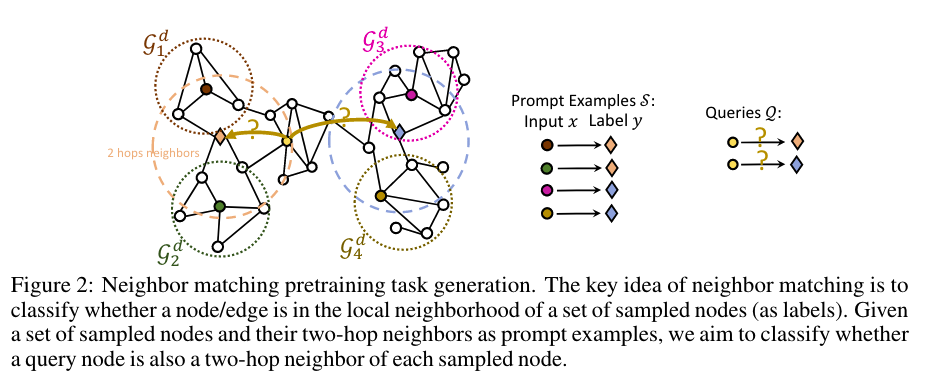
Pre-training Loss
- Pretrain the model with the cross-entropy objectives over generated
prompt graphs
- Pretrain the model with the cross-entropy objectives over generated
prompt graphs