
1 📑Metadata
信息
- 标题:Search to aggregate neighborhood for graph neural network
- 作者: Zhao, Huan; Yao, Quanming; Tu, Weiwei
- 团队: [[QuanmingYao]]
- 年份: 2021
- 主题:Method; NAS
- DOI: 10.48550/arXiv.2104.06608
- 开源:https://github.com/AutoML-4Paradigm/SANE
- 联动:[[DARTS:Differentiable Architecture Search]]
- PDF: arXiv.org Snapshot; Notion; Search to aggregate neighborhood for graph neural network_Zhao_2021.pdf
- 标签: #NAS #神经架构搜索 #可微 #图神经网络 #图神经架构搜索 #经典论文
标题
- Search to aggregate neighborhood for graph neural network
摘要
- Recent years have witnessed the popularity and success of graph neural networks (GNN) in various scenarios. To obtain data-specific GNN architectures, researchers turn to neural architecture search (NAS), which has made impressive success in discovering effective architectures in convolutional neural networks. However, it is non-trivial to apply NAS approaches to GNN due to challenges in search space design and the expensive searching cost of existing NAS methods. In this work, to obtain the data-specific GNN architectures and address the computational challenges facing by NAS approaches, we propose a framework, which tries to Search to Aggregate NEighborhood (SANE), to automatically design data-specific GNN architectures. By designing a novel and expressive search space, we propose a differentiable search algorithm, which is more efficient than previous reinforcement learning based methods. Experimental results on four tasks and seven real-world datasets demonstrate the superiority of SANE compared to existing GNN models and NAS approaches in terms of effectiveness and efficiency. (Code is available at: https://github.com/AutoML-4Paradigm/SANE).
2 💡Note
2.1 论文试图解决什么问题?
- It is non-trivial to apply NAS approaches to GNN due to challenges
in search space design and expensive searching cost of existing NAS
methods.
- The architecture and computational challenges facing existing GNN models and NAS approaches
2.2 这是否是一个新的问题?
No. Two preliminary works, GraphNAS and Auto-GNN, made the first attempt to tackle the architecture challenge in GNN with the NAS approaches.
2.3 这篇文章要验证一个什么科学假设?
By designing a novel and expressive search space, the differentiable search algorithm is more efficient than previous methods.
2.4 有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
2.4.1 GNN Baselines
- The embedding of a node
in the -th layer of a -layer GNN is computed as: - Four key components of a GNN model:
- Aggregation function (
) - SANE mainly focus on this.
- GCN, GraphSAGE, GAT, GIN, GeniePath
- Number of layers (
) - DropEdge
- PairNorm
- Neighbors (
) - GraphSaint
- Geom-GCN
- MixHop
- Hyper-parameters (
, dimension size, etc.)
- Aggregation function (
2.4.2 NAS
- Early NAS
- Follow a trial-and-error pipeline:
- RL-based search algorithms
very expensive in nature. - GraphNAS
- Auto-GNN
- Evolutionary-based search algorithm
inherently time-consuming.
- One-shot NAS
- Weight sharing strategy to reduce the computational cost.
- One can train a single large network (supernet) capable of emulating any architecture in the search space.
- Previous one-shot NAS approaches:
- [[DARTS:Differentiable Architecture Search|DARTS]] (CNN and RNN)
- NASP
- SANE (proposed in this paper):
- The search space is more expressive than GraphNAS and Auto-GNN.
- The first differentiable NAS approach for GNN.
2.5 🔴论文中提到的解决方案之关键是什么?
An illustration of the proposed framework:
1. Upper Left: an example graph with five nodes. The gray rectangle represents the input features of each node;
Bottom Left: a typical 3-layer GNN model following the message passing neighborhood aggregation schema, which computes the embeddings of node “2”;
The supernet for a 3-layer GNN and
represent, respectively, weight vectors for node aggregators, layer aggregators, and skip-connections in the corresponding edges. The rectangles denote the representations, out of which three green ones represent the hidden embeddings, gray and yellow ones represent the input and output embeddings, respectively, and blue one represents the set of output embeddings of three node aggregators for the layer aggregator.
2.5.1 Search Space
A good search space: 1. should be large and expressive enough to emulate various existing GNN models, thus ensures the competitive performance. 2. should be small and compact enough for the sake of computational resources.
- The operations using as node and layer aggregators for the search
space of SANE:

- More details:
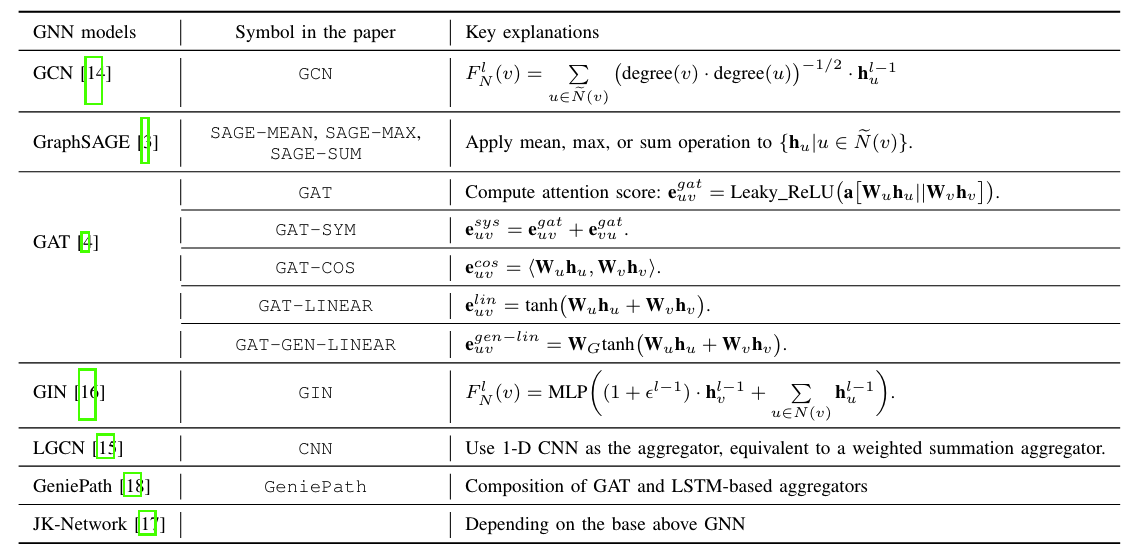
- Search space of SANE does not include hyper-parameters of GNN
models.
To decouple the architecture search and hyper-parameters tuning. - GNN models is mainly relying on the properties of the aggregation
functions.
- Node aggregators: to guarantee as powerful as possible the searched architectures.
- Layer aggregators: to alleviate the over-smoothing problems in deeper GNN models.
- The search space is made smaller in orders.
- GNN models is mainly relying on the properties of the aggregation
functions.
2.5.2 Search Strategy
2.5.2.1 Continuous Relaxation of the Search Space
Assume we use a K-layer GNN with JK-Network as backbone.
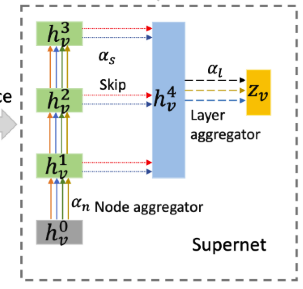
- Represent search space as a directed acyclic graph (DAG):
- Nodes (
): each node is a latent representation - One input nodes
- One output node
- One node representing the set of all skipped intermediated layers.
- K intermediate nodes.
- Edges: Each directed edge
is associated with an operation that transforms .
- Nodes (
- Relax the categorical choice of a particular operation to a softmax
over all possible operations:
: the operation mixing weights for a pair of nodes : : the input hidden features for a GNN layer : the mixed operations
- The neighborhood aggregation process by SANE:
- For the last layer:
- supernet: the summation of all operations
- After we obtain the final representation of the node
, we can inject it to different types of loss depending on the given task.
2.5.3 Performance Evaluation Strategy

- SANE is to solve a bi-level optimization problem as:
and are the training and validation loss. represents a network architecture. represents corresponding weights after training.
- Optimization by gradient descent
- Gradient-based approximation to update the architecture
parameters:
- Gradient-based approximation to update the architecture
parameters:
- After training, we retain the top-k strongest
operations.
- Then the searched architecture is retrained from scratch and tuned on the validation data to obtain the best hyper-parameters.
2.6 论文中的实验是如何设计的?
2.6.1 用于定量评估的数据集是什么?评估标准是什么?Baseline 是什么?
2.6.1.1 Transductive Task
- 数据集: Cora, CiteSeer, PubMed
- 任务:Node classification
- 输入: A subset of nodes in one graph is allowed to access as training data, and other nodes are used as validation and test data.
- 输出: Paper classification into different subjects
- 指标:
- 基线:
Human-designed GNN architectures
- GCN, GraphSAGE, GAT, GIN, LGCN, and GeniePath
- Variants: different aggregators in GraphSAGE
- GCN-JK, GraphSAGE-JK, GAT-JK, GIN-JK, GeniePath-JK
NAS approaches.

- Random search
- Bayesian optimization
- GraphNAS
- GraphNAS-WS(using weight sharing)
2.6.1.2 Inductive Task
- 数据集: PPI
- 任务:Graph classification
- 输入: A number of graphs as training data, and other completely unseen graphs as validation/test data.
- 输出: Protein classification into different functions
- 指标:
- 基线:
- Human-designed GNN architectures
- GCN, GraphSAGE, GAT, GIN, LGCN, and GeniePath
- Variants: different aggregators in GraphSAGE
- GCN-JK, GraphSAGE-JK, GAT-JK, GIN-JK, GeniePath-JK
- NAS approaches.
- Random search
- Bayesian optimization
- GraphNAS
- GraphNAS-WS(using weight sharing)
- Human-designed GNN architectures
2.6.1.3 DB Task
- 数据集: DBLP15K
- 任务:Cross-lingual entity alignment
- 输入: The subset of Chinese and English
- 输出: Matched entities referring to the same instances in different languages in two KBs.
- 指标:
- 基线:
- Human-designed GNN architectures
- GCN, GraphSAGE, GAT, GIN, LGCN, and GeniePath
- Variants: different aggregators in GraphSAGE
- GCN-JK, GraphSAGE-JK, GAT-JK, GIN-JK, GeniePath-JK
- NAS approaches.
- Random search
- Bayesian optimization
- GraphNAS
- GraphNAS-WS(using weight sharing)
- Human-designed GNN architectures
2.6.2 论文中的实验及结果有没有很好地支持需要验证的科学假设?
2.6.2.1 Performance on Transductive and Inductive Tasks
实验结果: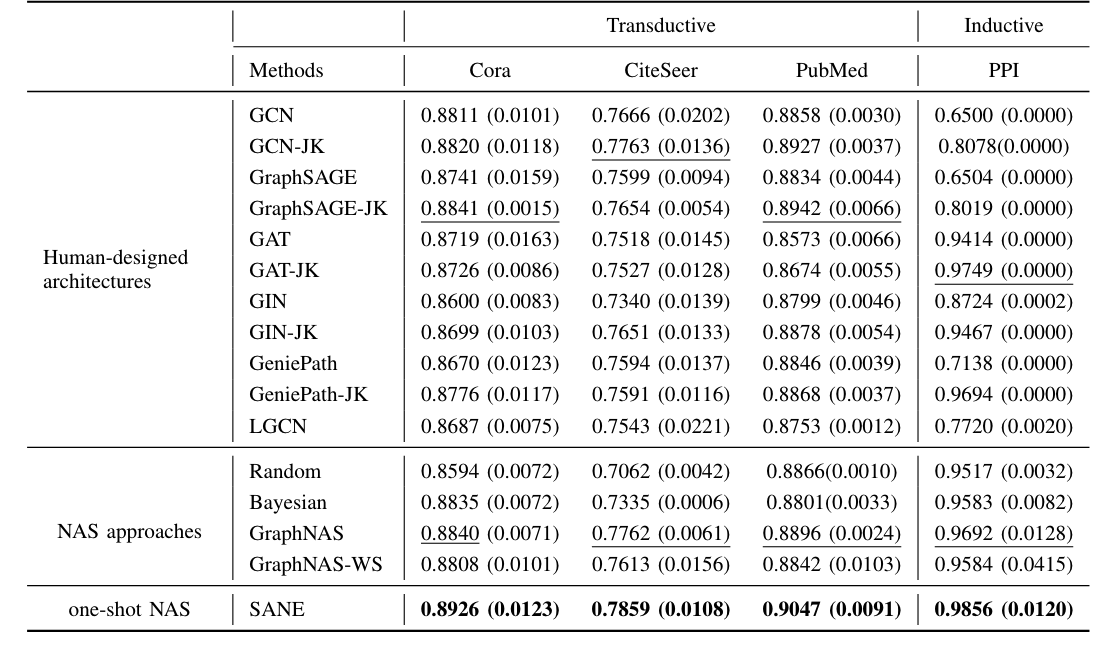
结论:
- Transductive Task:
- SANE consistently outperforms all baselines on three datasets, which demonstrates the effectiveness of the searched architectures by SANE.
- In terms of human-designed GNN, GCN and GraphSAGE outperform other
more complex models, attributed to the fact that these three graphs are
not that large, thus the complex aggregators might be easily prone to
the overfitting problem.
- No absolute winner: Verifying the need of searching for data-specific architectures.
- Adding JK-Network to base GNN architectures, the performance
increases consistently.
- Demonstrating the importance of introducing the layer aggregators into the search space
- Looking at the performance of NAS approaches
- Random Bayesian and GraphNAS all search in a discrete search space, while SANE searches in a differentiable one to find a better local optimal.
- Inductive Task:
- Seeing a similar trend.
- Searched Architectures
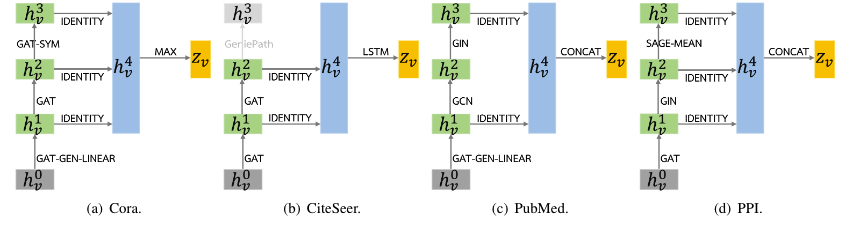
- Architectures are data-dependent and new to the literature.
- Searching for skip-connections indeed make a difference.
- GAT (and its variants) are more popularly used.
2.6.2.2 Search Efficiency
实验结果:
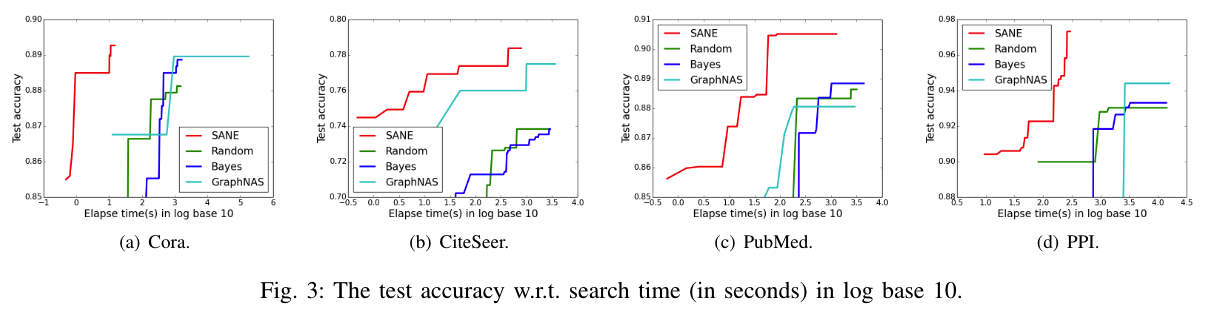
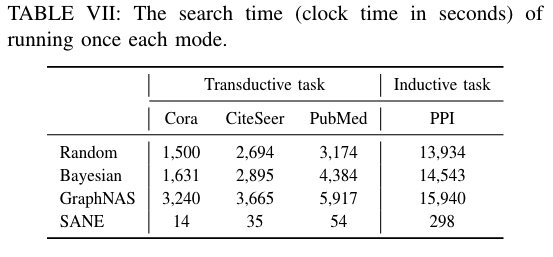
结论: 1. The efficiency improvements are in orders of magnitude. 2. SANE can obtain an architecture with higher test accuracy.
2.6.2.3 Ablation Study
实验结果: 1. The influence of differentiable search: 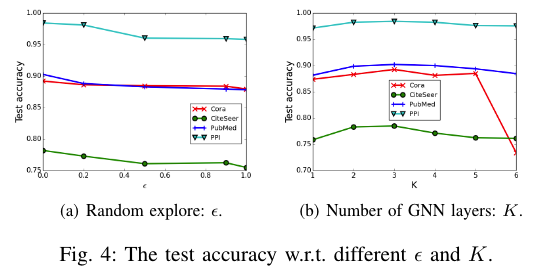 1. Introduce a random explore
parameter
1. Introduce a random explore
parameter  1. Run GraphNAS over its own and SANE’s search space,
given the same time budget (20 hours) 2. Compare the final test accuracy
of the searched architectures 4. Failure of searching for universal
approximators:
1. Run GraphNAS over its own and SANE’s search space,
given the same time budget (20 hours) 2. Compare the final test accuracy
of the searched architectures 4. Failure of searching for universal
approximators: 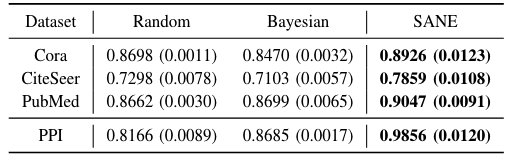 1. The hidden embedding size (width):
1. The hidden embedding size (width):
结论: 1. The gradient descent method outperforms random sampling for architecture search, demonstrating the effectiveness of the proposed differentiable search algorithm. 2. SANE can obtain better or at least close accuracy compared to GraphNAS, which means better architectures can be obtained given the same time budget, thus demonstrating the efficacy of the designed search space. 3. The performance gap between searching for MLP and SANE are large. Searching MLP as node aggregators is difficult, despite its powerful expressive capability as WL test. The designed search space of SANE including existing human-designed GNN models is necessary.
2.7 这篇论文到底有什么贡献?
- Designing a novel and expressive search space.
- The first differentiable NAS approach for GNN.
2.8 下一步呢?有什么工作可以继续深入?
- To explore beyond node classification tasks and focus on more
graph-based tasks, e.g., the whole graph classification
- Different graph pooling methods
- More expressive search space.
- Same problem as DARTS.