This paper addresses the scalability challenge of architecture search
by formulating the task in a differentiable manner. Unlike conventional
approaches of applying evolution or reinforcement learning over a
discrete and non-differentiable search space, our method is based on the
continuous relaxation of the architecture representation, allowing
efficient search of the architecture using gradient descent. Extensive
experiments on CIFAR-10, ImageNet, Penn Treebank and WikiText-2 show
that our algorithm excels in discovering high-performance convolutional
architectures for image classification and recurrent architectures for
language modeling, while being orders of magnitude faster than
state-of-the-art non-differentiable techniques. Our implementation has
been made publicly available to facilitate further research on efficient
architecture search algorithms.
1 💡Note
1.1 论文试图解决什么问题?
Dominant approaches treated the architecture search as a black-box
optimization problem over a discrete domain, leading to a large number
of architecture evaluation required.
Efficient architecture search
1.2 这是否是一个新的问题?
Numerous prior studies have explored various approaches based on
reinforcement learning (RL), evolution, or Bayesian optimization.
But DARTS approaches the problem from a different angle.
1.3
这篇文章要验证一个什么科学假设?
Compared with previous methods, differentiable network architecture
search based on bilevel optimization is efficient and
transferable.
1.4
有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
non-differentiable search techniques: reinforcement learning (RL),
evolution, or Bayesian optimization.
Low efficiency
searching architectures within a continuous domain
Seek to fine-tune a specific aspect of an architecture, as opposed
to learning high-performance architecture building blocks with complex
graph topologies with a rich search space.
1.5
🔴论文中提到的解决方案之关键是什么?
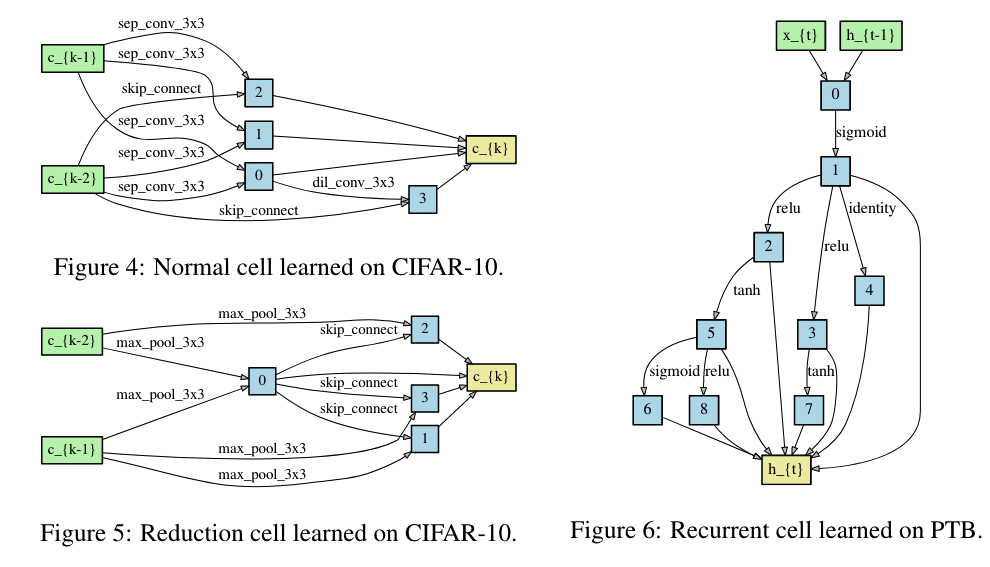
[!Note] An overview of DARTS (a)
Operations on the edges are initially unknown.
Continuous relaxation of the search space by placing a mixture of
candidate operations on each edge.
Joint optimization of the mixing probabilities and the network
weights by solving a bilevel optimization problem.
Inducing the final architecture from the learned mixing
probabilities.
Searching for a computation cell as the building
block of the final architecture.
A cell is a directed acyclic graph consisting of an
ordered sequence of N nodes.
Each node: latent representation
"Latent representation" refers to a representation form used in
machine learning and deep learning to represent hidden features or
abstract representations of data.
Each directed edge: operation
Each intermediate node is computed based on all of its predecessors:
A special zero operation is also included to indicate a lack of
connection between two nodes.
learning the cell
learning the operations on its edges.
1.5.2 Continuous
Relaxation And Optimization
Relaxation: Relax the categorical choice of a
particular operation to a softmax over all possible operations:
: the operation
mixing weights for a pair of nodes
learning a set of continuous variables
[[Bilevel optimization]]: After relaxation, our
goal is to jointly learn the architecture and the weights within all the mixed operations
optimize the validation loss, but using gradient descent.
the architecture could
be viewed as a special type of hyper-parameter
1.5.3 Approximate
Architecture Gradient
One-step Approximation: (Also can be seen in
Nesterov,MAML)Evaluating the architecture gradient exactly can be
prohibitive due to the expensive inner optimization.
helps to converge to a
better local optimum
Chain rule:
Let:
So:
Where:
And:
And:
So:
Finite difference approximation:The expression
above contains an expensive matrix-vector product in its second term.
Central difference:
Taylor Formula:
We have:
Then:
Replace with :
Subtract one equation from another:
Where:
First-order Approximation:, the second-order derivative will
disappear.
1.5.4 Deriving Discrete
Architectures
The strength of an operation is defined as .
Discretization: At the end of search, a discrete
architecture can be obtained by replacing each mixed operation with the
most likely operation
Retain the top-k strongest operations.
1.5.5 Complexity Analysis
1.6 论文中的实验是如何设计的?
1.6.1 Architecture Search
Search for the cell architectures using DARTS, and determine the best
cells based on their validation performance
operations sets:
Convolutional Cells(Order: ; N = 7 nodes):
3 × 3 and 5 × 5 separable convolutions
3 × 3 and 5 × 5 dilated separable convolutions
3 × 3 max pooling
3 × 3 average pooling
identity
zero
Recurrent Cells(N = 12 nodes):
linear transformations
tanh
relu
sigmoid
identity
zero
1.6.2 Architecture Evaluation
Use these cells to construct larger architectures, which we train
from scratch and report their performance on the test set.
To evaluate the selected architecture, randomly initialize its
weights (weights learned during the search process are discarded), train
it from scratch, and report its performance on the test set.
1.6.3 Parameter Analysis
1.6.3.1 Alternative
Optimization Strategies
and are jointly optimized over the union of
the training and validation sets using coordinate
descent
Even worse than random search
optimize simultaneously
with (without alteration) using
SGD
Worse than DARTS
1.6.3.2 Search with Increased
Depth
The enlarged discrepancy of the number of channels between
architecture search and final evaluation.
Searching with a deeper model might require different
hyper-parameters due to the increased number of layers to back-prop
through
1.7
论文中的实验及结果有没有很好地支持需要验证的科学假设?
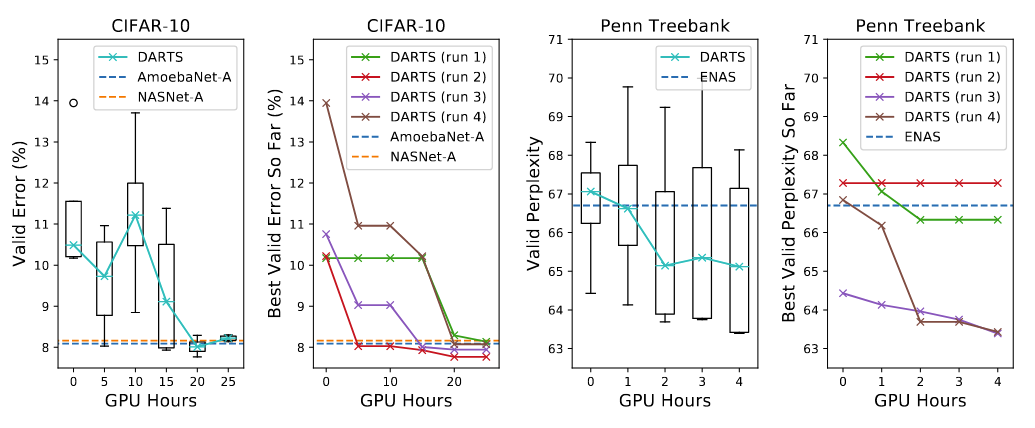
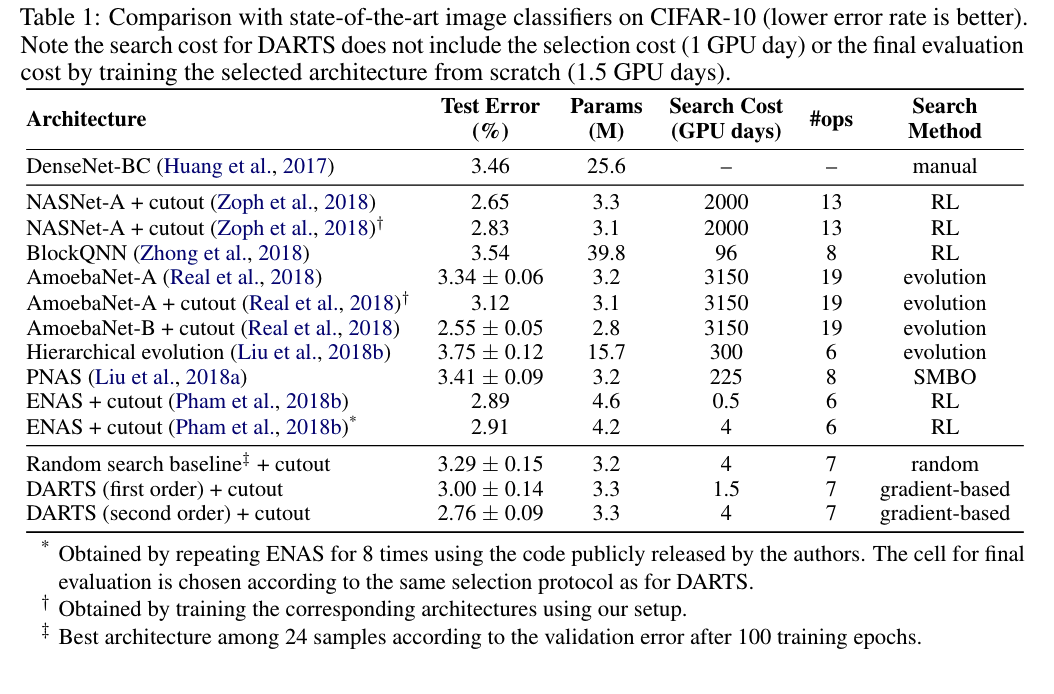
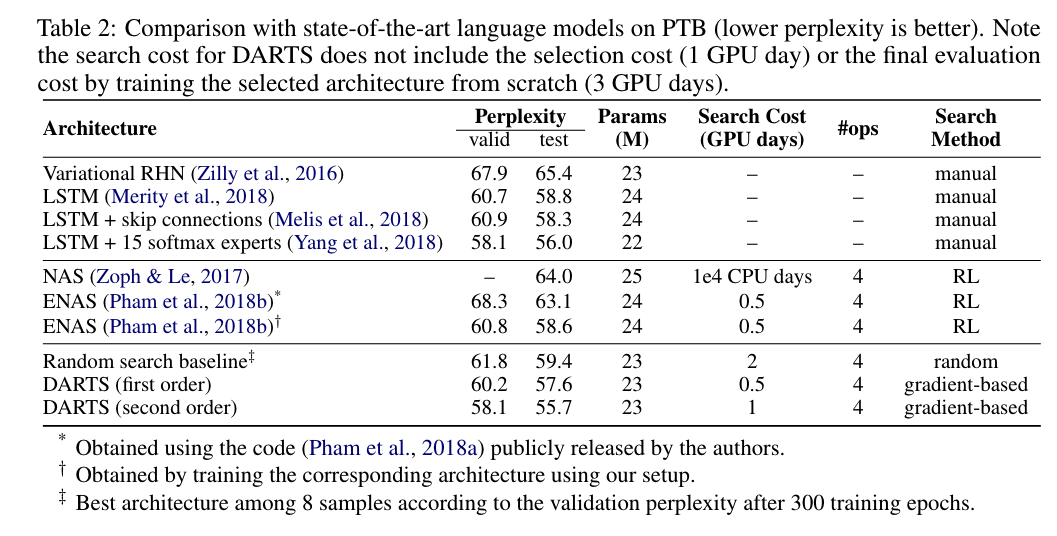
Result #1 :
Result #2 :
CIFAR-10
PTB
Result #3 :Transferability
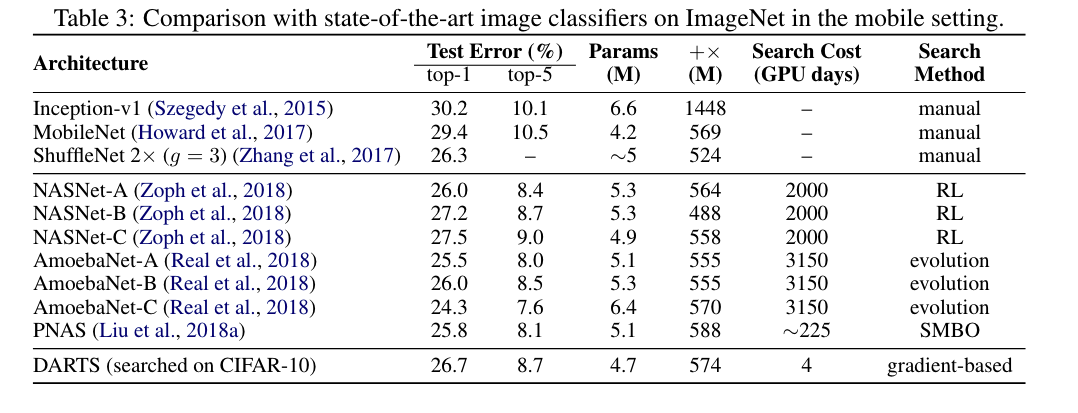
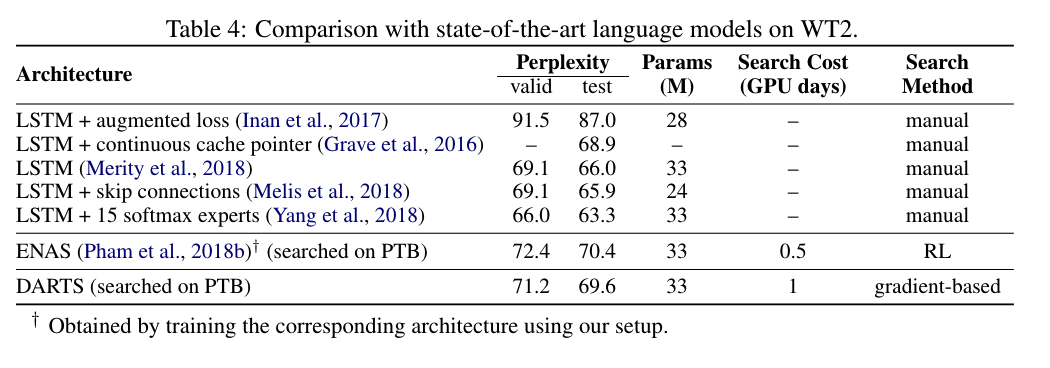
CIFAR-10 -> ImageNet
PTB -> WT2
1.8 这篇论文到底有什么贡献?
A novel algorithm for differentiable network architecture search
based on bilevel optimization.
Extensive experiments showing that gradient-based architecture
search achieves highly competitive results and remarkable efficiency
improvement.
Transferable architectures learned by DARTS.
1.9
下一步呢?有什么工作可以继续深入?
Differentiable architecture search on Graph neural networks.

(a) Operations on the edges are initially unknown.